
К середине 2025 года как минимум десять компаний, которые не владеют ни одной языковой моделью, преодолели отметку $100 млн годовой выручки. Cursor сделал это за 11 месяцев — быстрее, чем любой B2B-продукт в истории. Glean удвоил выручку с $100 до $200 млн за девять месяцев. ElevenLabs, два польских основателя которого начали с нуля в 2022 году, в 2026 году оценивается в $11 млрд. При этом все они работают поверх чужих моделей — OpenAI, Anthropic, Google, иногда нескольких сразу.
Расхожий тезис о том, что «обёртка умрёт, как только провайдер добавит эту фичу», не исчез. Его повторяют в Twitter, на конференциях и в питч-деках конкурентов. Но пока скептики рассуждают о платформенном риске, часть обёрток тихо превращается в настоящий бизнес с собственными данными, процессами и несколькими слоями защиты от копирования. Что именно отделяет выживших от мёртвых — разбираем ниже.
Что такое AI-обёртка и почему это не оскорбление
Обёртка (AI wrapper) — это продукт, который использует API сторонней языковой или мультимодальной модели как вычислительный движок, добавляя к нему собственный слой ценности. Это не презрительный ярлык: почти все вертикальные SaaS-продукты последних трёх лет строятся по этой схеме.
Спектр обёрток широк. На одном конце — тонкая обёртка: красивый UI над ChatGPT с фиксированным промптом и подпиской $9 в месяц. Она решает одну задачу (генерирует посты для LinkedIn, пишет email-шаблоны) и имеет ровно ноль барьеров для копирования. Любой другой разработчик может запустить конкурента за выходные. На другом конце — толстая обёртка: продукт, который берёт несколько базовых моделей, добавляет корпоративные данные клиента, встраивается в существующие процессы, делает точную настройку под отрасль и создаёт пользовательский опыт, который конкурент не скопирует за неделю. Разница между ними — не техническая, а экономическая и стратегическая.
Важно понять, чем обёртки отличаются от двух смежных категорий. AI-native компания строит собственные модели или значимо их модифицирует — это Anthropic, Mistral, Cohere. Классический SaaS добавляет AI как дополнительную функцию к продукту, который существовал до эпохи больших языковых моделей, — это Salesforce с Einstein или HubSpot с Breeze. Обёртка стоит посередине: её продукт возник благодаря языковым моделям и без них не имеет смысла, но модель она не создаёт.
Ключевое различие в позиционировании: обёртка конкурирует не с провайдером модели, а с горизонтальными инструментами вроде ChatGPT или Gemini. Её задача — быть лучше там, где «нативный» продукт провайдера заведомо плох: в вертикальной специализации, интеграции с корпоративными системами и пользовательском опыте, заточенном под конкретный сценарий.
Третий тип игроков, который часто путают с обёртками, — AI-агентные платформы. Они не просто оборачивают модель, а оркеструют несколько инструментов, баз данных и внешних сервисов вокруг одного сценария. Граница между «толстой обёрткой» и «агентной платформой» размыта и продолжает смещаться по мере того, как сами языковые модели становятся умнее. Для понимания бизнес-модели это различие важно: агентные продукты обычно дороже, сложнее в развёртывании и имеют более высокий switching cost.
Где деньги: экономика обёртки
Маржинальность обёрток ниже, чем у классического SaaS, — и это нужно принять как данность, а не скрывать. Традиционный SaaS на масштабе держит валовую маржу 75-90%: расходы на хостинг минимальны, а прирост выручки почти не требует пропорционального роста затрат. Для AI-продуктов картина другая.
По данным ICONIQ, в январе 2026 года средняя валовая маржа AI-компаний составила 52%, поднявшись с 41% в 2024 году. Стоимость инференса съедает примерно 23% выручки как отдельная строка COGS. Лучшие обёртки с глубокой вертикальной специализацией выходят на 60-65% — это структурный потолок для большинства сценариев использования.
Ценообразование обёрток делится на три схемы. Seat-based (плата за пользователя) работает там, где продукт используется регулярно и предсказуемо — корпоративные инструменты для написания, кодинга, поиска. Usage-based (плата за потребление) подходит для генерации видео, синтеза речи, обработки документов, где объём использования непредсказуем. Credits (кредиты) — гибрид: клиент покупает пул наперёд, компания получает деньги сразу, управляя балансом между объёмом и ценой.
«Налог модели» — зависимость от провайдера API — это реальная статья расходов. Компании, которые научились работать с несколькими провайдерами или перейти на более дешёвую модель при сохранении качества, получают операционное преимущество. Cursor, например, модель-агностик: поддерживает GPT-4, Claude и собственные fine-tuned модели одновременно. Это снижает риск концентрации у одного поставщика и позволяет выбирать наиболее дешёвый или точный вариант для каждого конкретного запроса.
Важная деталь о динамике маржи: стоимость инференса падает на 50-70% каждые 12 месяцев — это структурный тренд, подтверждённый несколькими циклами обновления моделей. Для обёрток с usage-based моделью это значит, что при сохранении цены для клиента валовая маржа будет расти сама по себе. Harvey и ElevenLabs уже фиксируют этот эффект: их COGS снижается, а выручка растёт.
Есть ещё один структурный сдвиг в экономике обёрток: enterprise-контракты меняют всю модель. Компании, которые перешли от PLG (product-led growth) к enterprise-продажам, сообщают о контрактах от $500 тыс. до $5 млн в год. При такой средней сделке валовая маржа менее важна, чем CAC и retention. Glean, Harvey, Writer — все они движутся в этом направлении. Writer в 2024 году достиг $84 млн ARR при оценке $1.9 млрд, обслуживая Uber, Spotify, L'Oreal через enterprise-контракты. Это принципиально другая экономическая модель, чем подписка $49 в месяц.
| Компания | ARR (2025-2026) | Модель монетизации | Расчётная валовая маржа |
|---|---|---|---|
| Cursor | $2 млрд (февр. 2026) | Seat-based, $20/мес | ~55-60% |
| Glean | $300 млн (май 2026) | Enterprise contracts | ~60-65% |
| Harvey | $300 млн (май 2026) | Enterprise SaaS | ~65% |
| ElevenLabs | $500 млн (апр. 2026) | Usage-based + enterprise | ~50-55% |
| Perplexity | $450 млн (март 2026) | Freemium + Pro $20/мес | ~55-60% |
Кейсы: кто выжил и почему
Jasper: как умирает тонкая обёртка
Jasper — самый цитируемый кейс провала, хотя история сложнее, чем кажется. Компания появилась в 2021 году как инструмент для генерации маркетинговых текстов и за год выросла до $125 млн ARR к концу 2022 года, привлекла $125 млн при оценке $1.5 млрд. Это был феноменальный рост — быстрее большинства SaaS-компаний того же периода.
Проблема возникла в ноябре 2022 года, когда OpenAI запустил ChatGPT. Jasper продавал удобный доступ к GPT-3 с готовыми шаблонами. Когда тот же GPT стал бесплатным и доступным напрямую, основное предложение продукта испарилось. К 2024 году выручка упала примерно до $55 млн — на 54% от пика. Летом 2023-го прошли сокращения, внутренняя оценка срезана на 20%. Трафик сайта упал с 8.7 млн до 6.1 млн посетителей в месяц за несколько недель.
Что пошло не так структурно: Jasper строил шаблоны, а не данные. Его ценность — это удобство, а не знание. ChatGPT оказался достаточно удобен сам по себе, и разрыв между Jasper и «просто ChatGPT» стал слишком мал для $49 в месяц.
Компания выжила за счёт разворота в сторону enterprise: к маю 2025 года число корпоративных клиентов превысило 900, включая почти 20% из Fortune 500, а enterprise ARR утроился. Это классическая история pivot: компания нашла аудиторию, где удобство плюс брендинг плюс корпоративные стандарты работают как аргумент. Но стартовые $1.5 млрд оценки при тонкой продуктовой механике — дорогой урок для рынка.
Cursor: как построить $2 млрд на чужих моделях
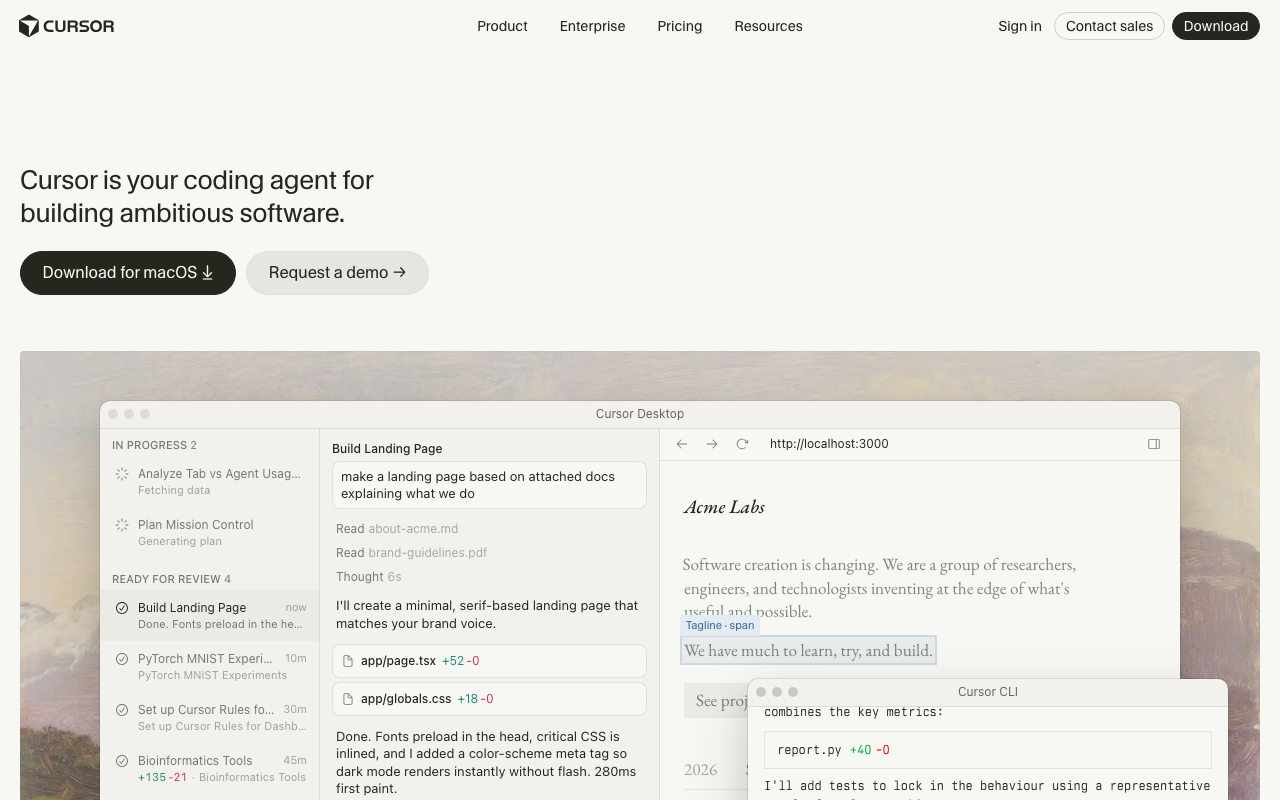 Cursor позиционирует себя как «coding agent для амбициозного софта» — не плагин к IDE, а целая рабочая среда.
Cursor позиционирует себя как «coding agent для амбициозного софта» — не плагин к IDE, а целая рабочая среда.
Cursor — кейс, который сложнее всего объяснить скептикам. Это редактор кода, основанный на Visual Studio Code (открытый исходный код Microsoft), работающий на GPT-4 и Claude, конкурирующий с GitHub Copilot, за которым стоят ресурсы Microsoft и данные 100 млн разработчиков. На бумаге — обречён.
В феврале 2026 года Cursor достиг $2 млрд ARR, в ноябре 2025-го привлёк $2.3 млрд при оценке $29.3 млрд. За три года с нуля до $2 млрд — рекорд среди всех B2B-продуктов в истории. Платящих клиентов — больше 1 млн, среди них 70% компаний из Fortune 1 000.
Механика защиты — не в модели, а в редакторе. Cursor работает на уровне всего проекта: при автодополнении он анализирует все файлы репозитория, понимает зависимости, предлагает импорты из соседних модулей. GitHub Copilot исторически работал на уровне текущего файла. Cursor индексирует кодовую базу семантически — это дорого в COGS, но создаёт качество, которое разработчики чувствуют при первом же сеансе. Функция Composer позволяет описать рефакторинг на естественном языке и получить согласованные изменения сразу в десятках файлов.
Кроме того, Cursor агностичен к провайдеру модели: когда Claude стал лучше GPT-4 на определённых задачах, Cursor просто добавил его. Переключение пользователей на GitHub Copilot требует смены всей рабочей среды — высокий switching cost. Разработчик, который три месяца проработал в Cursor и настроил под себя правила, история чатов и конфигурации, не меняет редактор ради 10-долларовой разницы в подписке.
Perplexity: поиск как сервис
Perplexity начинал как «AI-ответчик» поверх веб-поиска и языковых моделей. Его угол — не генерация текста, а разрушение классической поисковой воронки: вместо списка ссылок пользователь получает синтезированный ответ с источниками. Это, казалось бы, ровно то, что Google мог выкатить как обновление за три месяца.
К марту 2026 года ARR превысил $450 млн — более чем удвоившись за квартал после новых продуктов и изменения ценообразования. Оценка компании в сентябре 2025 года составила $20 млрд при раунде на $200 млн. Среди инвесторов — Nvidia, Jefff Bezos (личные деньги), SoftBank.
Защита Perplexity строится на двух слоях. Первый — собственный индекс веба и инфраструктура поиска в реальном времени: это уже не просто вызов API языковой модели, это самостоятельная система с краулерами, кэшами и алгоритмами ранжирования. Создать её с нуля — вопрос не месяцев, а лет. Второй — пользовательские привычки: 780 млн запросов в месяц по состоянию на середину 2025 года создают массив данных о том, как люди ищут информацию. Google потенциально может скопировать интерфейс, но не мгновенно переучить 100 млн активных пользователей Perplexity.
Synthesia: B2B-видео без видеостудии
 «All-in-one AI Video platform for business» — Synthesia целится в корпоративное видео, не в TikTok-ролики.
«All-in-one AI Video platform for business» — Synthesia целится в корпоративное видео, не в TikTok-ролики.
Synthesia — лондонский стартап, который создаёт видео с AI-аватарами для корпоративного обучения, маркетинга и клиентской поддержки. Клиент загружает скрипт, выбирает аватар и язык — видео готово за минуты без камеры и актёров.
В апреле 2025 года компания объявила о преодолении $100 млн ARR, в сентябре 2025 года ARR достиг $146 млн, к 2026 году — $150 млн и выше с прицелом на $200 млн. В январе 2026 года закрыт раунд Series E на $200 млн при оценке $4 млрд с участием Nvidia и VC-подразделения Alphabet.
70% выручки Synthesia — enterprise. Более 80% компаний из Fortune 100 — клиенты. Это не случайность: корпоративное видео — одна из немногих ниш, где критична регуляторная сторона (брендинг аватаров, согласие актёров, локализация на 140+ языков). Synthesia построила вокруг этого юридическую и техническую инфраструктуру, которую тяжело воспроизвести без аналогичных лет работы с enterprise-клиентами. Барьер — не алгоритм генерации видео, а библиотека из сотен лицензированных аватаров, многолетние отношения с корпоративными покупателями и соответствие требованиям безопасности данных крупных организаций. Конкурент, который хочет войти в этот рынок, должен пройти procurement в 100 компаниях заново.
Glean: поиск по корпоративным знаниям
 Glean соединяет знания, системы и контекст компании — корпоративный поиск нового типа.
Glean соединяет знания, системы и контекст компании — корпоративный поиск нового типа.
Glean делает то, что корпоративный Google так и не сделал: ищет по всем рабочим инструментам сразу — Slack, Notion, Salesforce, Google Drive, Jira — и отвечает на вопросы с учётом контекста конкретной компании. Не «найди документ», а «скажи мне, как у нас устроен процесс онбординга нового клиента».
В декабре 2025 года компания объявила о достижении $200 млн ARR — удвоившись за девять месяцев с $100 млн. К маю 2026 года ARR превысил $300 млн. Оценка в июне 2025 года — $7.2 млрд. Компания работает в 27 странах, штат — более 1 000 человек.
Защита Glean — в данных клиента и глубине интеграции. Настройка Glean под конкретную компанию занимает недели: коннекторы к десяткам систем, настройка разрешений, обучение модели на внутренних документах. После этого Glean знает терминологию компании, её продукты, внутренние аббревиатуры. Перенести это в конкурирующий продукт — значит пройти весь путь заново и потерять три-шесть месяцев продуктивности. Сегмент контрактов $1 млн+ почти утроился за год: крупный enterprise платит больше именно потому, что уходить слишком дорого.
Harvey: юридическая вертикаль
 «Practice Made Perfect» — среди клиентов Harvey: PwC, Bridgewater, McKinsey.
«Practice Made Perfect» — среди клиентов Harvey: PwC, Bridgewater, McKinsey.
Harvey — узкоспециализированная обёртка для юристов. Помогает с due diligence, составлением договоров, исследованием прецедентов, анализом регуляторики. Работает поверх Claude и GPT-4, но добавляет специфику, которую горизонтальная модель не даст: знание юридических баз данных, форматов документов, отраслевых стандартов.
Выручка Harvey к концу 2023 года составляла $10 млн ARR, в 2024-м — $65.8 млн (+558% год к году). В августе 2025 года преодолён рубеж $100 млн ARR, к маю 2026 года — $300 млн ARR по оценке Sacra. В марте 2026 года компания оценена в $11 млрд. Клиенты — глобальные юридические фирмы, а также крупные корпорации: NBCUniversal, HSBC.
Ключевая защита — доверие отрасли. Юридическая фирма не переключится на незнакомый инструмент, если её нынешний держит конфиденциальность, понимает прецедентное право и не галлюцинирует в документах, которые пойдут в суд. Harvey инвестирует в точность выше рыночной нормы и в соответствие регуляторным требованиям (GDPR, attorney-client privilege). Репутация здесь — не маркетинговый актив, а барьер для конкурентов. Кроме того, Harvey строит модели на юридических данных совместно с крупными клиентами — это fine-tuning, недоступный конкуренту без аналогичных партнёрств.
ElevenLabs: голос как инфраструктура
ElevenLabs — польско-американский стартап, основанный Пётром Добри (Piotr Dobry) и Матеушем Станишевским (Mateusz Staniszewski). Начинал с клонирования голоса по короткой аудиозаписи, сейчас предлагает API для синтеза речи на 70+ языках, озвучки контента, создания голосовых агентов.
К апрелю 2026 года ARR достиг $500 млн — с нуля за три года. В феврале 2026 года привлечено $500 млн при оценке $11 млрд с участием Sequoia и Andreessen Horowitz. 41% компаний из Fortune 500 используют ElevenLabs — по выручке $825 тыс. на сотрудника, один из лучших показателей в индустрии.
Защита здесь многоуровневая. Во-первых, сетевой эффект данных: чем больше голосов в библиотеке, тем меньше клиенту нужно создавать собственные. Во-вторых, switching cost через голосовую идентичность: компания, которая встроила конкретный голос в свои продукты (от рекламы до IVR-системы), не захочет его менять. Аудитория привыкает к голосу бренда так же, как к логотипу. В-третьих, B2B-интеграции на уровне контрактов: Washington Post, HarperCollins, Revolut — каждый из них встроил ElevenLabs глубоко в продуктовый стек.
Lovable: пример за пределами США
 Lovable целит в тех, кто не умеет программировать: «Build something Lovable» через текстовые команды.
Lovable целит в тех, кто не умеет программировать: «Build something Lovable» через текстовые команды.
Lovable — шведский стартап из Стокгольма, который превратил разработку приложений в текстовые команды. Пользователь описывает, что хочет сделать, — Lovable генерирует работающий код и разворачивает приложение. Это не игрушка: продукт строят реальные компании для реальных нужд.
$100 млн ARR за восемь месяцев после запуска в конце 2024 года, к маю 2026 года — $500 млн ARR по оценке Sacra. В декабре 2025 года закрыт раунд $330 млн при оценке $6.6 млрд. Среди клиентов — Klarna, Uber, Zendesk. За первый год существования на платформе создано более 25 млн проектов.
Lovable ориентируется на аудиторию, которая никогда не программировала: дизайнеры, маркетологи, основатели без технического образования. Это другой рынок, чем у Cursor или GitHub Copilot. Пользовательская база в 8 млн человек и более 25 млн созданных проектов создают сетевой эффект: шаблоны, примеры, публичные демо привлекают новых пользователей. Переключиться на конкурента означает заново строить весь контекст и потерять историю проектов, накопленных за месяцы работы.
Пять паттернов выживших обёрток
Из восьми кейсов выше можно выделить пять механик, которые отделяют устойчивый бизнес от временного явления.
Вертикальная специализация
Harvey не делает «AI для всех». Glean не делает «AI для поиска вообще». Они берут конкретную отрасль или сценарий — юридические документы, корпоративные знания, медицинские записи — и строят продукт, который знает эту нишу глубже, чем горизонтальная модель когда-либо сможет знать по умолчанию. Отраслевые данные для точной настройки, специфические форматы, регуляторные требования — всё это барьеры, которые горизонтальный продукт не преодолеет без аналогичных инвестиций. OpenAI не станет специализироваться на прецедентном праве конкретной юрисдикции так же глубоко, как Harvey. Рынок слишком мал для них, но достаточно велик для вертикального игрока.
Собственные данные и точная настройка
Обёртки, которые аккумулируют данные пользователей — историю запросов, исправленные ошибки, одобренные ответы — могут переучивать модели под конкретный контекст. Perplexity строит собственный поисковый индекс. Glean обучает модель на внутренних документах клиента. Это создаёт эффект, при котором продукт с каждым месяцем использования становится лучше именно для этого клиента — и хуже для конкурента, которого позвали на замену. Чем дольше клиент работает с продуктом, тем точнее модель под него настроена, тем дороже переключение.
Switching cost через интеграцию в процессы
Самая недооценённая механика. Когда Glean подключён к 40 корпоративным системам, настроен под права доступа конкретного сотрудника и знает терминологию компании — переключиться стоит не $X в месяц, а несколько месяцев работы IT-отдела. ElevenLabs, встроенный в продуктовый стек через API, тоже не меняют ради 10% экономии. Глубина интеграции — лучший долгосрочный барьер, потому что он не зависит от того, кто придумал лучший алгоритм: он зависит от стоимости замены.
Сетевой эффект через пользовательский контент
Lovable, Midjourney, ElevenLabs работают по похожей схеме: пользователи создают контент (приложения, изображения, голоса), часть его становится общедоступной библиотекой, которая привлекает новых пользователей. Это классический UGC-маховик, перенесённый в AI-продукт. Чем больше голосов в библиотеке ElevenLabs, тем ценнее подписка — и тем меньше смысла в конкурирующем продукте с пустой библиотекой. Новый конкурент не может скопировать три года UGC за три месяца.
Скорость итерации и UX-превосходство
Cursor вырос не потому, что его модели лучше, чем у GitHub Copilot. Он вырос потому, что команда быстрее добавляла функции, которые просили разработчики, и создавала опыт, заточенный под одну задачу — кодинг, — а не пыталась угодить всем. Это временное преимущество, которое нужно постоянно поддерживать. Но оно реально работает, пока конкурент занят корпоративными согласованиями и backlog-менеджментом на пять команд. Скорость — тоже барьер, если её удерживать систематически.
Обёртки в РФ и СНГ: реалистичный сценарий
Российский рынок AI-продуктов развивается в своей изоляции. Совокупная выручка топ-35 поставщиков ИИ-решений в России достигла ₽43 млрд в 2024 году при росте более 80%. Большую часть этой суммы генерируют крупные интеграторы — Сбер, Яндекс, «Газпром-ИС» — а не независимые стартапы. Независимый рынок AI-продуктов для малого и среднего бизнеса практически не занят.
Модельная инфраструктура для обёрток есть. YandexGPT (YandexGPT 5.1 Pro) предлагает API через Yandex Cloud с ценообразованием, оптимизированным для рублёвого рынка, и хорошо работает на русскоязычных задачах. GigaChat от Сбера снизил стоимость API до 40 копеек за 1 000 токенов — это дешевле многих западных аналогов. Open-source модели (LLaMA, Mistral, DeepSeek) доступны без ограничений и разворачиваются локально, что важно для корпоративных клиентов с требованиями к суверенитету данных.
Регуляторика создаёт одновременно ограничения и возможности. 152-ФЗ о персональных данных требует хранения данных на территории РФ — это барьер для использования западных облачных API, но плюс для локальных обёрток. Госзаказ предпочитает отечественные решения: обёртка поверх YandexGPT или GigaChat с нужными сертификатами выигрывает тендер у аналога на OpenAI. Это не временная мера — это структурное преимущество для локального игрока на пять-семь лет минимум.
Вертикали с потенциалом в РФ: юридические документы, медицинские записи (ФОМС, ЕГР), строительная документация, корпоративный поиск в промышленных компаниях — те же паттерны, что работают глобально, только с русскоязычными данными и локальным compliance. Конкурировать нужно не с Jasper, а с Excel-таблицами, самописными скриптами и отсутствием автоматизации вообще.
Реалистичный сценарий для соло-основателя: выбрать узкую отрасль, добавить отраслевые данные через RAG или fine-tuning, получить два-три anchor-контракта с enterprise-клиентами, которые делают продукт незаменимым. Горизонт до первых ₽1 млн выручки в месяц — реалистичен за 12-18 месяцев при правильном выборе ниши. Горизонт до ₽10 млн MRR требует нескольких enterprise-контрактов и интеграций, которые создают высокий switching cost. Ничего из этого не требует написания собственной языковой модели.
Один честный ограничитель: российский рынок меньше американского в 10-15 раз по числу платёжеспособных корпоративных покупателей. Это значит, что потолок обёртки в РФ — $5-20 млн ARR, а не $300 млн. Но для соло-основателя или небольшой команды это вполне достижимый и привлекательный размер бизнеса. Harvey прошёл путь от $0 до $10 млн ARR за два года в одной юрисдикции — аналогичный сценарий в российской юридической нише или медицине выглядит вполне выполнимым.
Три реальных риска
Платформенный риск. OpenAI добавит «Projects» с памятью, Anthropic запустит Business-план с кастомными инструкциями, Google Gemini получит интеграцию с корпоративными системами — и часть тонких обёрток просто исчезнет. Это уже происходит: Jasper потерял больше половины выручки именно по этой причине. Защита — не быть тонкой обёрткой, а строить что-то, что сложнее скопировать за одно обновление продукта.
Сжатие маржи. Стоимость инференса падает быстро — это хорошо для экономики продукта, но конкуренты и клиенты давят на цену в том же направлении. Компании с usage-based моделью чувствуют это острее всего: падение стоимости токена на 50% транслируется в давление на ARR, если не наращивать объёмы. Обёртки с seat-based или enterprise-договорами защищены лучше, потому что цена фиксирована на уровне ценности, а не на уровне стоимости инференса.
Зависимость от одного API. Если вся инфраструктура продукта строится на одном провайдере, один инцидент (outage, изменение условий, поднятие цены) выключает бизнес. Cursor решил это за счёт мультипровайдерной архитектуры. Компании поменьше делают то же самое через OpenRouter или самостоятельно поддерживая несколько провайдеров. Диверсификация на уровне API-провайдеров — базовая операционная гигиена для любого AI-продукта с выручкой выше $1 млн.
Что из этого следует для основателя
Страх «OpenAI добавит эту фичу» — не аргумент против обёртки. Это аргумент против тонкой обёртки. Разница между Jasper 2022 года и Harvey 2025 года — не в технологии. Один продавал доступ к модели, другой строил знание отрасли, доверие клиентов и инфраструктуру соответствия требованиям. Первое копируется за ночь, второе — нет.
Для соло-основателя сегодня это означает одно: выбери нишу, где данные трудно собрать, процессы трудно автоматизировать без понимания отрасли, и клиенты не переключаются после первого успешного внедрения. Там обёртка будет жить дольше, чем большинство стартапов, которые строят модели с нуля и тратят $50 млн на compute до первой выручки.